LLMs Can Get "Brain Rot"!
TL;DR
Researchers found that large language models decline in reasoning, long-context understanding, and safety when trained on low-quality web text. This decline is caused by the models truncating or skipping reasoning chains, leading to persistent representational drift. The study used controlled experiments on Twitter corpora and found that the popularity of a tweet is a better indicator of the decline than its length. This matters because it highlights the importance of data quality in training language models, which are used in many real-world applications. By improving data quality, we can improve the safety and reliability of language models.
Technical Abstract
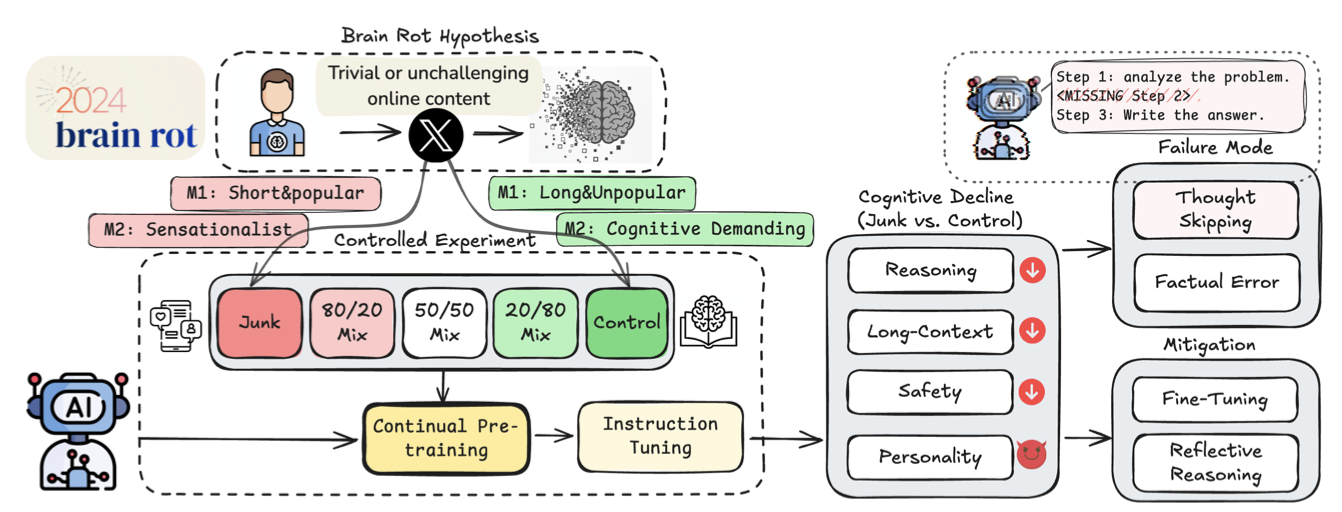
We propose and test the LLM Brain Rot Hypothesis: continual exposure to junk web text induces lasting cognitive decline in large language models (LLMs). To causally isolate data quality, we run controlled experiments on real Twitter/X corpora, constructing junk and reversely controlled datasets via two orthogonal operationalizations: M1 (engagement degree) and M2 (semantic quality), with matched token scale and training operations across conditions. Contrary to the control group, continual pre-training of 4 LLMs on the junk dataset causes non-trivial declines (Hedges' ) on reasoning, long-context understanding, safety, and inflating "dark traits" (e.g., psychopathy, narcissism). The gradual mixtures of junk and control datasets also yield dose-response cognition decay: for example, under M1, ARC-Challenge with Chain Of Thoughts drops and RULER-CWE as junk ratio rises from to . Error forensics reveal several key insights. First, we identify thought-skipping as the primary lesion: models increasingly truncate or skip reasoning chains, explaining most of the error growth. Second, partial but incomplete healing is observed: scaling instruction tuning and clean data pre-training improve the declined cognition yet cannot restore baseline capability, suggesting persistent representational drift rather than format mismatch. Finally, we discover that the popularity, a non-semantic metric, of a tweet is a better indicator of the Brain Rot effect than the length in M1. Together, the results provide significant, multi-perspective evidence that data quality is a causal driver of LLM capability decay, reframing curation for continual pretraining as a training-time safety problem and motivating routine "cognitive health checks" for deployed LLMs.
Why This Matters
This research matters because it highlights the importance of data quality in training language models, which are used in many real-world applications. Poor data quality can lead to declines in safety and reliability, which can have significant consequences. By improving data quality, we can improve the safety and reliability of language models, which can benefit scientists, industry, and society.